@Override public SourceVersion getSupportedSourceVersion() { return SourceVersion.latest(); }
@Override public Set<String> getSupportedAnnotationTypes() { HashSet<String> set = newHashSet<>(); set.add(TrisceliVersion.class.getName()); // 支持解析的注解 return set; }
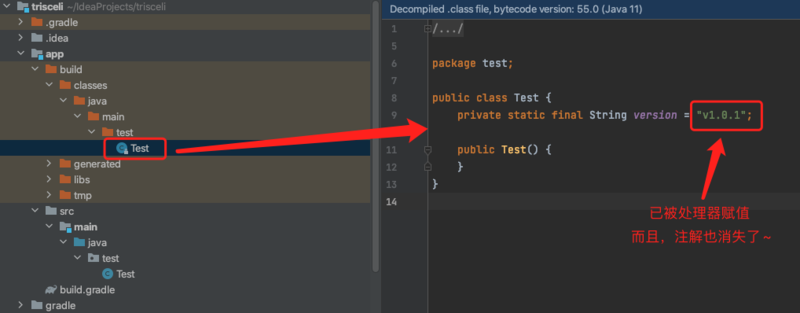
@Override publicbooleanprocess(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) { for (TypeElement t : annotations) { for (Element e : roundEnv.getElementsAnnotatedWith(t)) { // 获取到给定注解的element(element可以是一个类、方法、包等) // JCVariableDecl为字段/变量定义语法树节点 JCTree.JCVariableDecljcv= (JCTree.JCVariableDecl) javacTrees.getTree(e); StringvarType= jcv.vartype.type.toString(); if (!"java.lang.String".equals(varType)) { // 限定变量类型必须是String类型,否则抛异常 printErrorMessage(e, "Type '" + varType + "'" + " is not support."); } jcv.init = treeMaker.Literal(getVersion()); // 给这个字段赋值,也就是getVersion的返回值 } } returntrue; }
/** * 利用processingEnv内的Messager对象输出一些日志 * * @param e element * @param m error message */ privatevoidprintErrorMessage(Element e, String m) { processingEnv.getMessager().printMessage(Diagnostic.Kind.ERROR, m, e); }